Upgrading mautrix-signal to v0.5.x
The mautrix-signal matrix application recently announced an
update to v0.5.0, which involves a significant change to how it
works. Previously (e.g. in v0.4.3), the application depended on a
running instance of signald to integrate mautrix-signal with
the signal network. Starting with v0.5.0, this dependency is no
longer there, as the application can now integrate directly.
Unfortunately, the upgrade documentation … [more >>]
An interview with Colm O'Regan on The Function Room podcast
Yesterday, on the 13th December, the first of this year's two days of the earliest sunset, Colm O'Regan dropped episode 38 of his The Function Room podcast, with the title The Auld Sthretch with Éibhear Ó hAnluain.
It was a fun chat, recorded on the previous day. In the e-mail discussion plannign the session, Colm pointed out how I previously said the following regarding a 3 … [more >>]
Are you an average voter?
Way back in the mists of time, I was peripherally involved in the campaign to prevent the introduction of an electronic voting system in Ireland.
There was something that irritated me greatly about the conversations among those I campaigned with. It was the frequent use of the term average voter when referring to everyone else not involved one way or another in the campaign.
I still hear the term being used in similar or other contexts, and I believe it's condescending in its … [more >>]
Sunset times pages for The Grand Auld Sthretch
I maintain a set of pages on this site that give the sunrise, sunset, solar noon, daylight hours and length-of-stretch for each day of each "operational year" for The Grand Auld Sthretch.
Here are links to the pages, and the months of each year. I'll add to this page as I generate additional information each year.
2024
December 2023 … [more >>]
Views on the Fediverse regarding mandatory voting
The #Fediverse is fun. One of the more fun accounts is @RickiTarr@beige.party. Ricki has a practice of asking simple but probing questions for her followers to answer, which they do in great volume.
On the 4th November 2023, Ricki posed this question:
Do you think voting should be mandatory?
BE NICE!
It's a topic I've thought about a lot over the years, and I was interested in … [more >>]
Some Regulatory Concerns for Those Hosting Their Own Instances
The following is an edited version of a proposal I wrote for the Bluesky Community, now called the dSocialCommons, back in February 2022.
I'm reproducing it here to make it easy for me to share.
Purpose
This document lays out concerns for "self hosters" of services that contribute to the decentralised or #fediverse. At present, these concerns are not addressed in any … [more >>]
Social Gibiris is back online
Social Gibiris is back online. \o/
It has been a while.
Back in 2015, I set up a GNU Social instance on an AWS server, accessible at the address social.gibiris.org, very much to learn about both. Because GNU Social was software for federated microblogging, I hooked up with a lot of like-minded people from all around the world, and from whom I learned a lot about self-hosting of services and the fediverse … [more >>]
Org Reveal and gridded layouts
As is likely to be obvious to readers of this web site, also called a "blog", I am a big fan of GNU/Emacs and, particularly, org-mode.
I use org-mode for all my writings, and all my information analyses. The posts and pages of this web site are all written with org-mode. My CV is prepared in org-mode before being converted to … [more >>]
Fighting disinformation requires us all to contribute
I encountered two interesting conversations on twitter today, leading me to the conclusion that we won't be able to comprehensively deal with disinformation online any time soon.
The first is the following from Tadhg Hickey:
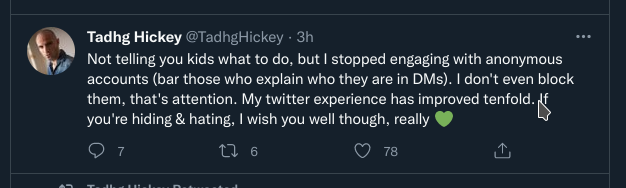
If you can't read that screen-grab, this is what he says:
Not telling you kids what to do, but I stopped engaging with
… [more >>]
Comparing Y2K action against Climate Inaction
In November 2021, David Quinn tweeted the following:
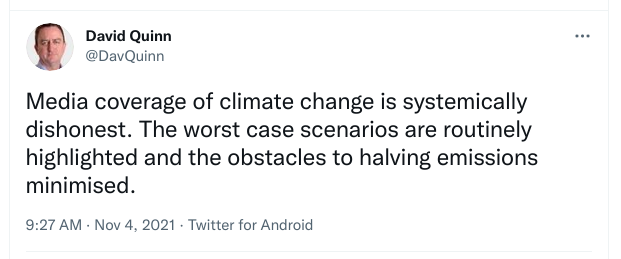
I quote-tweeted a response to that, and I am including it here, in slightly-edited form, to make sure it's preserved.
I first heard of Climate Change (then called Global Warming) in 1981/2, while I was still in primary school.
I first heard of the Y2K problem … [more >>]
